常⻅概念
在正式引⼊架构演进之前,为避免读者对架构中的概念完全不了解导致低效沟通,优先对其中⼀ 些⽐较重要的概念做前置介绍:
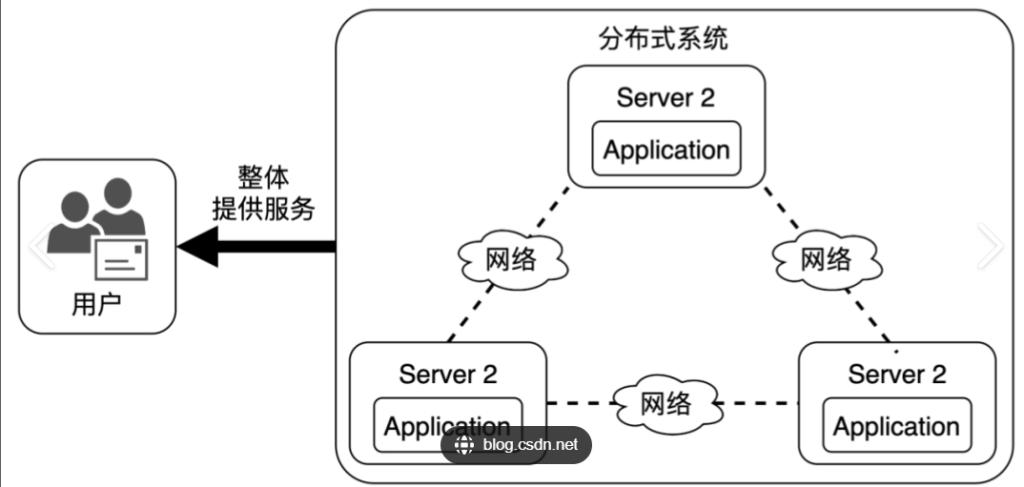
基本概念
应⽤(Application)/ 系统(System)
为了完成⼀整套服务的⼀个程序或者⼀组相互配合的程序群。⽣活例⼦类⽐:为了完成⼀项任 务,⽽搭建的由⼀个⼈或者⼀群相互配的⼈组成的团队。
模块(Module)/ 组件(Component)
当应⽤较复杂时,为了分离职责,将其中具有清晰职责的、内聚性强的部分,抽象出概念,便于 理解。⽣活例⼦类⽐:军队中为了进⾏某据点的攻克,将⼈员分为突击⼩组、爆破⼩组、掩护⼩组、 通信⼩组等。
分布式(Distributed)
系统中的多个模块被部署于不同服务器之上,即可以将该系统称为分布式系统。如 Web 服务器与 数据库分别⼯作在不同的服务器上,或者多台 Web 服务器被分别部署在不同服务器上。⽣活例⼦类 ⽐:为了更好的满⾜现实需要,⼀个在同⼀个办公场地的⼯作⼩组被分散到多个城市的不同⼯作场地 中进⾏远程配合⼯作完成⽬标。跨主机之间的模块之间的通信基本要借助⽹络⽀撑完成。
集群(Cluster)
被部署于多台服务器上的、为了实现特定⽬标的⼀个/组特定的组件,整个整体被称为集群。⽐如 多个 MySQL ⼯作在不同服务器上,共同提供数据库服务⽬标,可以被称为⼀组数据库集群。⽣活例⼦ 类⽐:为了解决军队攻克防守坚固的⼤城市的作战⽬标,指挥部将⼤批炮兵部队集中起来形成⼀个炮 兵打击集群。
分布式 vs 集群。
通常不⽤太严格区分两者的细微概念,细究的话,分布式强调的是物理形态,即 ⼯作在不同服务器上并且通过⽹络通信配合完成任务;⽽集群更在意逻辑形态,即是否为了完成特定 服务⽬标。
主(Master)/ 从(Slave)
集群中,通常有⼀个程序需要承担更多的职责,被称为主;其他承担附属职责的被称为从。⽐如 MySQL 集群中,只有其中⼀台服务器上数据库允许进⾏数据的写⼊(增/删/改),其他数据库的数据 修改全部要从这台数据库同步⽽来,则把那台数据库称为主库,其他数据库称为从库。
中间件(Middleware)
⼀类提供不同应⽤程序⽤于相互通信的软件,即处于不同技术、⼯具和数据库之间的桥梁。⽣活 例⼦类⽐:⼀家饭店开始时,会每天去市场挑选买菜,但随着饭店业务量变⼤,成⽴⼀个采购部,由 采购部专职于采买业务,称为厨房和菜市场之间的桥梁。
评价指标(Metric)
可⽤性(Availability)
考察单位时间段内,系统可以正常提供服务的概率/期望。例如: 年化系统可⽤性 = 系统正常提供服务时⻓ / ⼀年总时⻓。这⾥暗含着⼀个指标,即如何评价系统提供⽆法是否正常,我们就不深⼊了。平时我们常说的 4 个 9 即系统可以提供 99.99% 的可⽤性,5 个 9 是 99.999% 的可⽤性,以此类推。我们平时只是⽤⾼可⽤(High Availability HA)这个⾮量化⽬标简要表达我们系统的追求。
响应时⻓(Response Time RT)
指⽤⼾完成输⼊到系统给出⽤⼾反应的时⻓。例如点外卖业务的响应时⻓ = 拿到外卖的时刻 – 完成点单的时刻。通常我们需要衡量的是最⻓响应时⻓、平均响应时⻓和中位数响应时⻓。这个指标原则上是越⼩越好,但很多情况下由于实现的限制,需要根据实际情况具体判断
吞吐(Throughput)vs 并发(Concurrent)
吞吐考察单位时间段内,系统可以成功处理的请求的数量。并发指系统同⼀时刻⽀持的请求最⾼量。例如⼀条辆⻋道⾼速公路,⼀分钟可以通过 20 辆⻋,则并发是 2,⼀分钟的吞吐量是 20。实践中,并发量往往⽆法直接获取,很多时候都是⽤极短的时间段(⽐如 1 秒)的吞吐量做代替。我们平时⽤⾼并发(Hight Concurrnet)这个⾮量化⽬标简要表达系统的追求。
架构
单机架构
初期,我们需要利⽤我们精⼲的技术团队,快速将业务系统投⼊市场进⾏检验,并且可以迅速响应变化要求。但好在前期⽤⼾访问量很少,没有对我们的性能、安全等提出很⾼的要求,⽽且系统架构简单,⽆需专业的运维团队,所以选择单机架构是合适的。
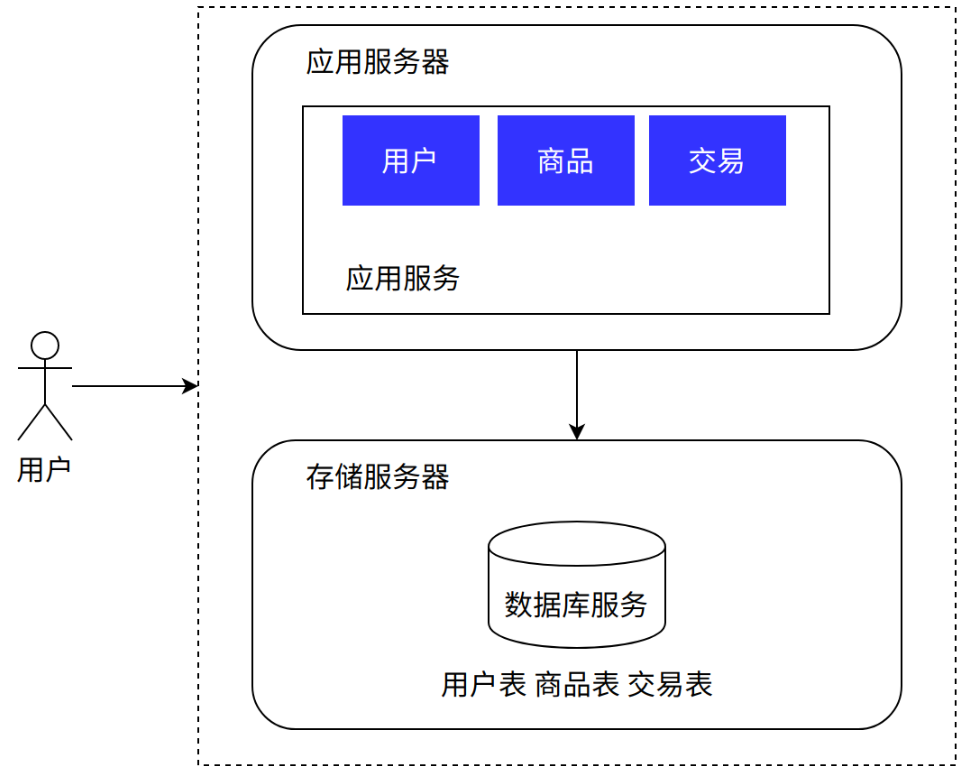
⽤⼾在浏览器中输⼊ www.bit.com,⾸先经过 DNS 服务将域名解析成 IP 地址 10.102.41.1,随后浏览器访问该 IP 对应的应⽤服务。
相关软件 Web 服务器软件:Tomcat、Netty、Nginx、Apache 等 数据库软件:MySQL、Oracle、PostgreSQL、SQL Server 等
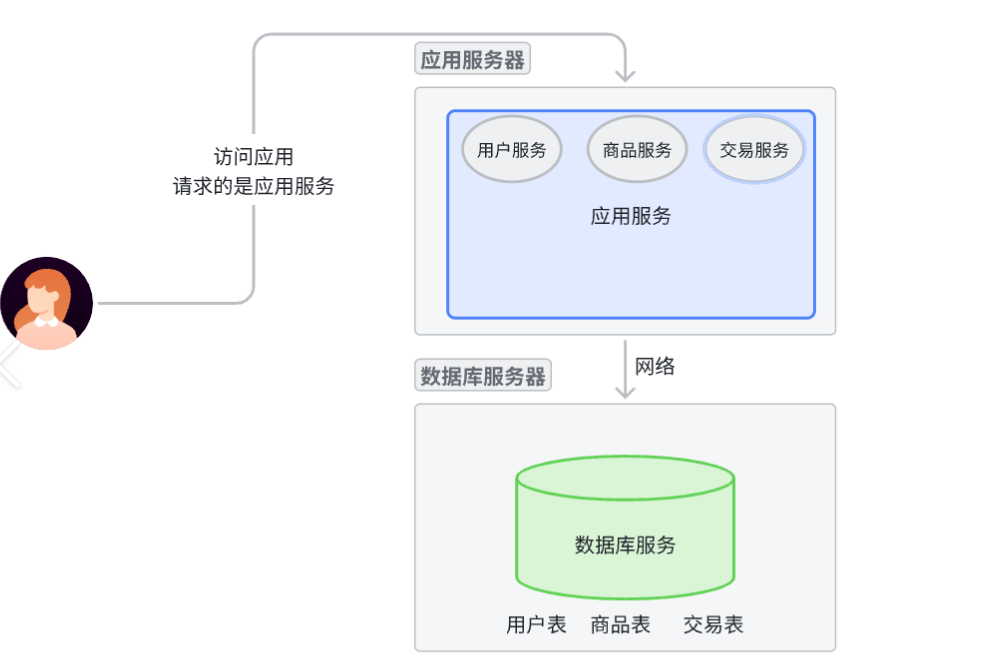
应⽤数据分离架构
随着系统的上线,我们不出意外地获得了成功。市场上出现了⼀批忠实于我们的⽤⼾,使得系统的访问量逐步上升,逐渐逼近了硬件资源的极限,同时团队也在此期间积累了对业务流程的⼀批经验。⾯对当前的性能压⼒,我们需要未⾬绸缪去进⾏系统重构、架构挑战,以提升系统的承载能⼒。但由于预算仍然很紧张,我们选择了将应⽤和数据分离的做法,可以最⼩代价的提升系统的承载能⼒。
应⽤服务集群架构
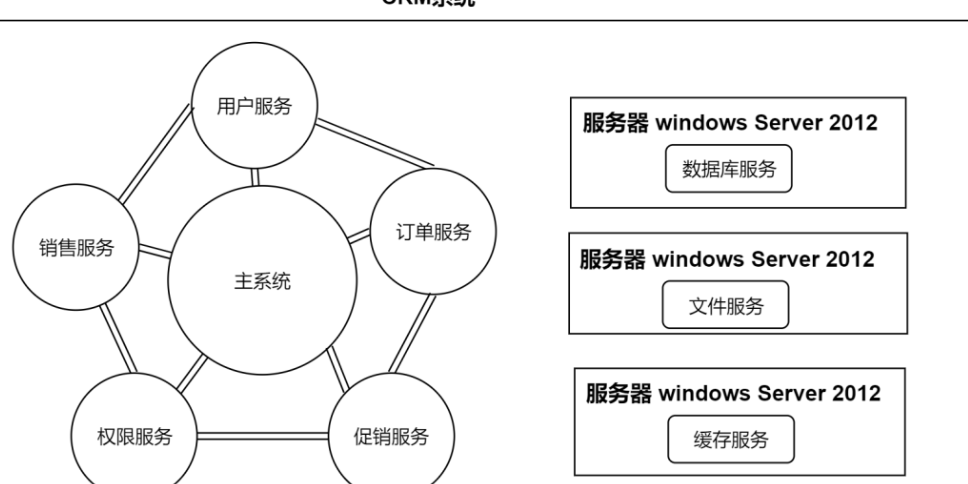
我们的系统受到了⽤⼾的欢迎,并且出现了爆款,单台应⽤服务器已经⽆法满⾜需求了。我们的单机应⽤服务器⾸先遇到了瓶颈,摆在我们技术团队⾯前的有两种⽅案,⼤家针对⽅案的优劣展⽰了热烈的讨论:
• 垂直扩展 / 纵向扩展 Scale Up。通过购买性能更优、价格更⾼的应⽤服务器来应对更多的流量。这种⽅案的优势在于完全不需要对系统软件做任何的调整;但劣势也很明显:硬件性能和价格的增⻓关系是⾮线性的,意味着选择性能 2 倍的硬件可能需要花费超过 4 倍的价格,其次硬件性能提升是有明显上限的。
• ⽔平扩展 / 横向扩展 Scale Out。通过调整软件架构,增加应⽤层硬件,将⽤⼾流量分担到不同的应⽤层服务器上,来提升系统的承载能⼒。这种⽅案的优势在于成本相对较低,并且提升的上限空间也很⼤。但劣势是带给系统更多的复杂性,需要技术团队有更丰富的经验。经过团队的学习、调研和讨论,最终选择了⽔平扩展的⽅案,来解决该问题,但这需要引⼊⼀个新的组件 ⸺ 负载均衡:为了解决⽤⼾流量向哪台应⽤服务器分发的问题,需要⼀个专⻔的系统组件做流量分发。
相关软件 负载均衡软件:Nginx、HAProxy、LVS、F5 等
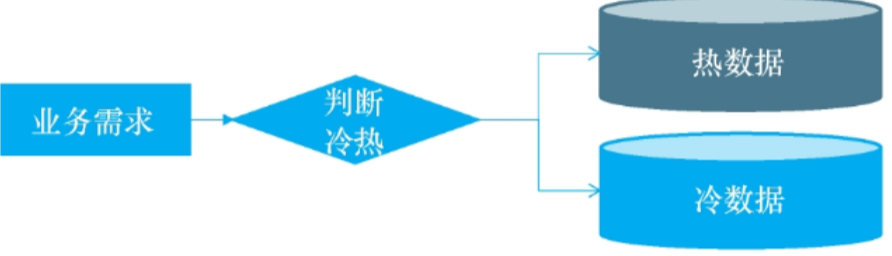
引⼊缓存 ⸺ 冷热分离架构
随着访问量继续增加,发现业务中⼀些数据的读取频率远⼤于其他数据的读取频率。我们把这部分数据称为热点数据,与之相对应的是冷数据。针对热数据,为了提升其读取的响应时间,可以增加本地缓存,并在外部增加分布式缓存,缓存热⻔商品信息或热⻔商品的 html ⻚⾯等。通过缓存能把绝⼤多数请求在读写数据库前拦截掉,⼤⼤降低数据库压⼒。其中涉及的技术包括:使⽤memcached作为本地缓存,使⽤ Redis 作为分布式缓存,还会涉及缓存⼀致性、缓存穿透/击穿、缓存雪崩、热点数据集中失效等问题。
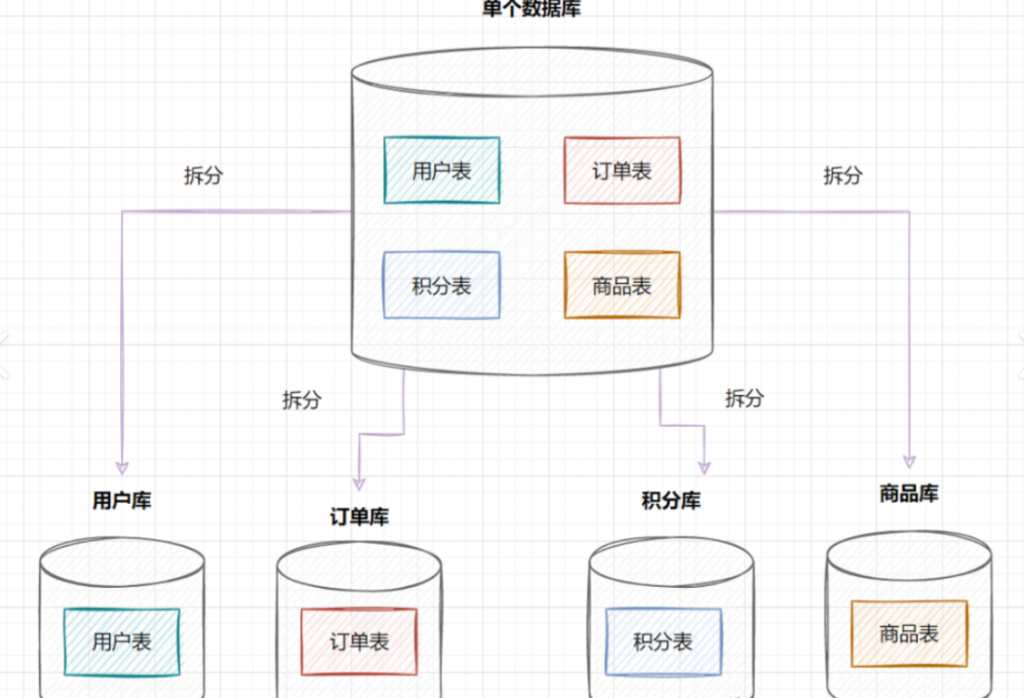
垂直分库
随着业务的数据量增⼤,⼤量的数据存储在同⼀个库中已经显得有些⼒不从⼼了,所以可以按照业务,将数据分别存储。⽐如针对评论数据,可按照商品ID进⾏hash,路由到对应的表中存储;针对⽀付记录,可按照⼩时创建表,每个⼩时表继续拆分为⼩表,使⽤⽤⼾ID或记录编号来路由数据。只要实时操作的表数据量⾜够⼩,请求能够⾜够均匀的分发到多台服务器上的⼩表,那数据库就能通过⽔平扩展的⽅式来提⾼性能。其中前⾯提到的Mycat也⽀持在⼤表拆分为⼩表情况下的访问控制。这种做法显著的增加了数据库运维的难度,对DBA的要求较⾼。数据库设计到这种结构时,已经可以称为分布式数据库,但是这只是⼀个逻辑的数据库整体,数据库⾥不同的组成部分是由不同的组件单独来实现的,如分库分表的管理和请求分发,由Mycat实现,SQL的解析由单机的数据库实现,读写分离可能由⽹关和消息队列来实现,查询结果的汇总可能由数据库接⼝层来实现等等,这种架构其实是MPP (⼤规模并⾏处理)架构的⼀类实现。
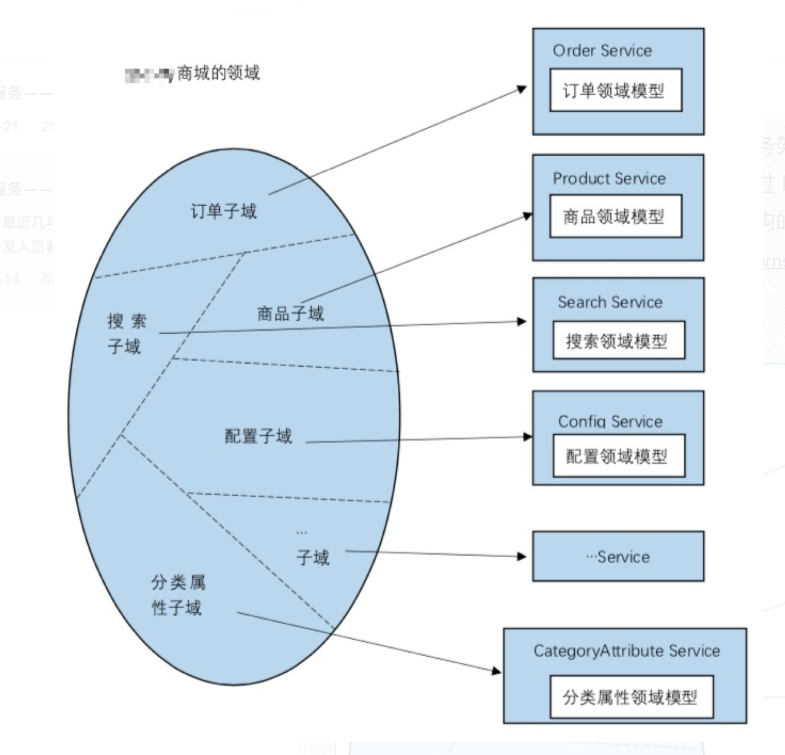
业务拆分 ⸺ 微服务
随着⼈员增加,业务发展,我们将业务分给不同的开发团队去维护,每个团队独⽴实现⾃⼰的微服务,然后互相之间对数据的直接访问进⾏隔离,可以利⽤ Gateway、消息总线等技术,实现相互之间的调⽤关联。甚⾄可以把⼀些类似⽤⼾管理、安全管理、数据采集等业务提成公共服务。
至此一个合理的分布式系统就完成了
今天的更新就到这里了,如有错误欢迎指出!
评论
还没有任何评论,你来说两句吧!