项目完整代码:https://gitee.com/tgwTTT/high-concurrency-memory-pool
前言
为什么要自己造轮子?
现代很多的开发环境都是多核多线程,在申请内存的场最下,必然存在激烈的锁竞争问题。malloc本身其实已经很优秀,但是传统的glibc中的malloc和Free页存在很多缺陷,
比如:1.多线程共享同一把 arena 锁,核数越多,越像单车道收费站,CPU 空转排队。
2.每次按需 brk/mmap,进内核、出内核,几十微秒起步等。
基于以上情况:我们的内存银行需要考虑许多情况
1.性能问题。
2.多线程环境下,锁竞争问题。
3.内存碎片问题。
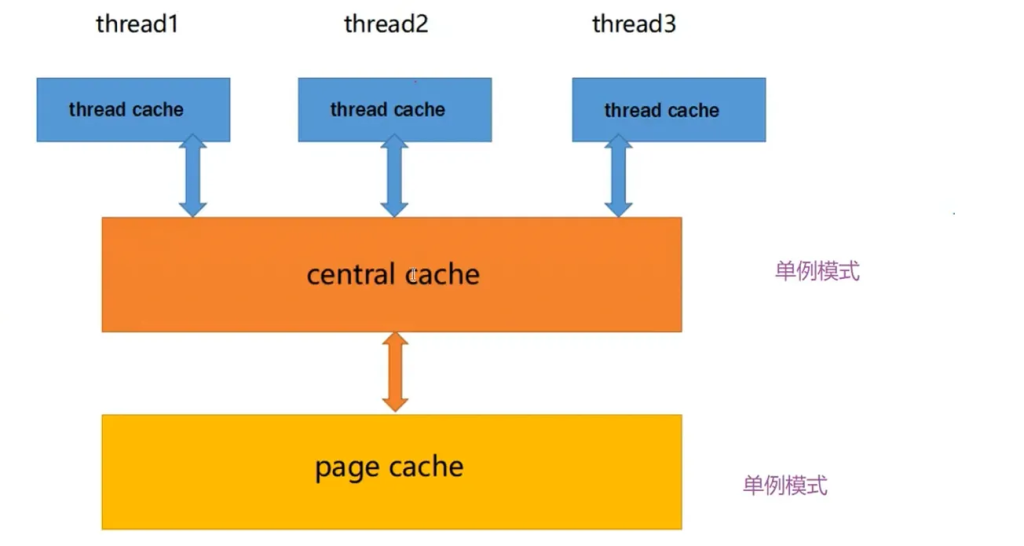
项目整体框架
项目整体框架分为3个部分:
1.threadCache
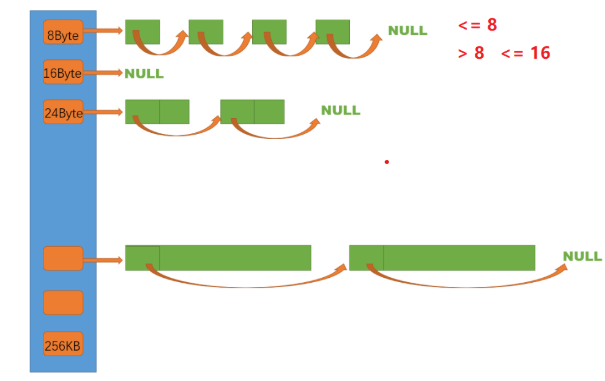
2.CnetralCache
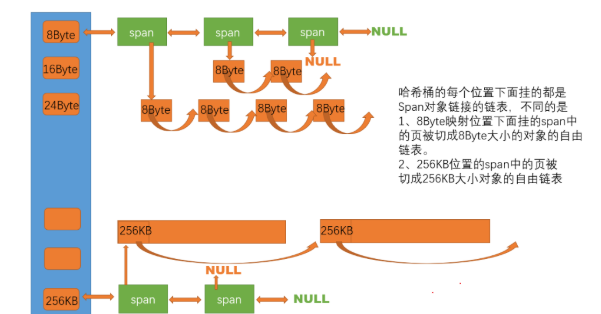
3.PageCache
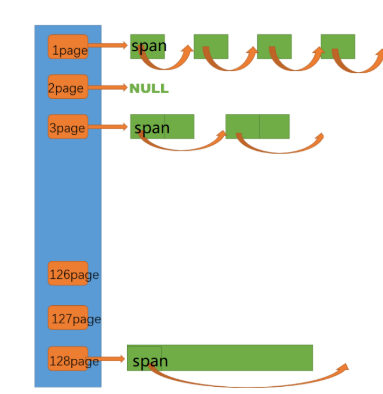
项目图及其整体框架如下:
具体设计解析
什么是内存池?
1.池化技术
所谓“池化技术”,就是程序先向系统申请过量的资源,然后⾃⼰管理,以备不时之需。之所以要申请过量的资源,是因为每次申请该资源都有较⼤的开销,不如提前申请好了,这样使⽤时就会变得⾮常快捷,⼤⼤提⾼程序运⾏效率。在计算机中,有很多使⽤“池”这种技术的地⽅,除了内存池,还有连接池、线程池、对象池等。以服务器上的线程池为例,它的主要思想是:先启动若⼲数量的线程,让它们处于睡眠状态,当接收到客⼾端的请求时,唤醒池中某个睡眠的线程,让它来处理客⼾端的请求,当处理完这个请求,线程⼜进⼊睡眠状态。
2.内存池
内存池是指程序预先从操作系统申请⼀块⾜够⼤内存,此后,当程序中需要申请内存的时候,不是直接向操作系统申请,⽽是直接从内存池中获取;同理,当程序释放内存的时候,并不真正将内存返回给操作系统,⽽是返回内存池。当程序退出(或者特定时间)时,内存池才将之前申请的内存真正释放。
3.内存池主要解决的问题
内存池主要解决的当然是效率的问题,其次如果作为系统的内存分配器的⻆度,还需要解决⼀下内存碎⽚的问题。
那么什么是内存碎⽚呢?
内存碎⽚分为外碎⽚和内碎⽚
外碎片:
外部碎⽚是⼀些空闲的连续内存区域太⼩,这些内存空间不连续,以⾄于合计的内存⾜够,但是不能满⾜⼀些的内存分配申请需求
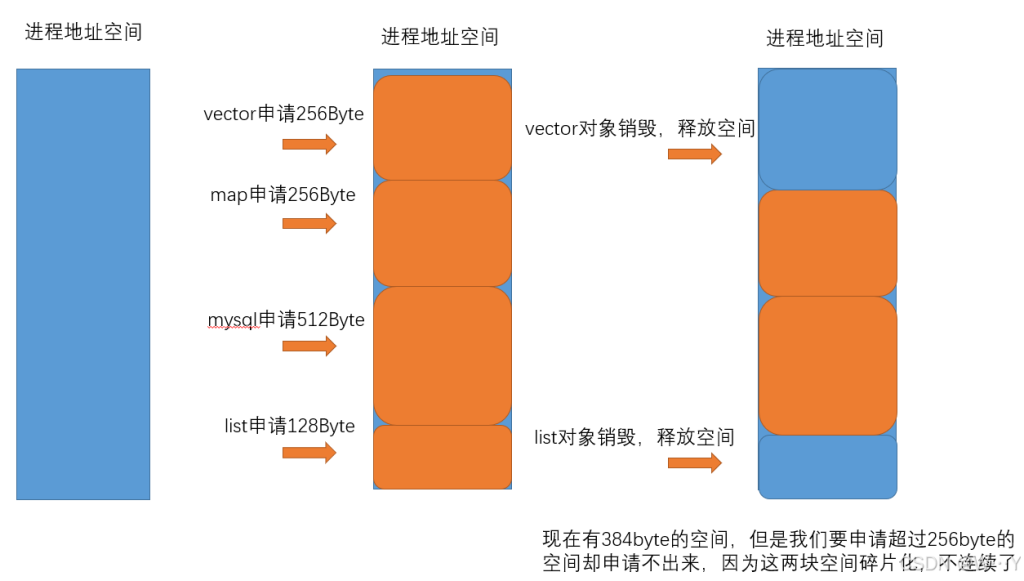
内部碎⽚是由于⼀些对⻬的需求,导致分配出去的空间中⼀些内存⽆法被利⽤。
开胃菜
先设计⼀个定⻓的内存池 作为程序员(C/C++)我们知道申请内存使⽤的是malloc,malloc其实就是⼀个通⽤的⼤众货,什么场景下都可以⽤,但是什么场景下都可以⽤就意味着什么场景下都不会有很⾼的性能,下⾯我们就先来设计⼀个定⻓内存池做个开胃菜,当然这个定⻓内存池在我们后⾯的⾼并发内存池中也是有价值的,所以学习他⽬的有两层,先熟悉⼀下简单内存池是如何控制的,第⼆他会作为我们后⾯内存池的⼀个基础组件。
具体请参考文章:http://www.tgwttt.xyz/?p=118
高性能内存池三层具体介绍:
ThreadCache (TLS) → CentralCache (全局) → PageCache (全局)
无锁分配 桶+自旋锁 按页合并/拆分1. thread cache:线程缓存是每个线程独有的,⽤于⼩于256KB的内存的分配,线程从这⾥申请内存不需要加锁,每个线程独享 208 条 FreeList(8 B ~ 256 KB,按 Size-Class 对齐)。
分配路径:Allocate() → 本线程 freelist.Pop() → 命中则直接返回,全程无锁。
2.CentralCache:全局 208 个 SpanList,每条链挂「已切好」的 Span(小块内存)。
ThreadCache 空时批量拿 batchNum 个对象回去;回收时链表过长再批量归还。
锁粒度:每条 SpanList 一把自旋锁
3.PageCache:
向 OS 批量拿内存(VirtualAlloc/mmap)
合并空闲 Span,缓解外碎片
建立页号 → Span 的哈希映射,方便回收时反向查找
核心功能及其代码实现
一、ThreadCache 层(TLS,无锁)
extern thread_local ThreadCache* pTLSThreadCache; // 每个线程一份
// ThreadCache.cc
void* ThreadCache::Allocate(size_t size){
size_t index = SizeClass::Index(size); // 映射到桶
if (!_freeLists[index].Empty()) // 本线程 freelist 有存货
return _freeLists[index].Pop(); // 直接 Pop,无锁路径结束
return FetchFromCentralCache(index, size); // 缺货→下一层
}
TLS介绍:线程局部存储(TLS),是一种变量的存储方法,这个变量在它所在的线程内是全局可访问的,但是不能被其他线程访问到,这样就保持了数据的线程独立性。而熟知的全局变量,是所有线程都可以访问的,这样就不可避免需要锁来控制,增加了控制成本和代码复杂度。
本质:线程局部存储(TLS),可以存储只能该线程使用的数据。
二、ThreadCache → CentralCache 批量补货// ThreadCache.cc
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size){
size_t batchNum = min(_freeLists[index].MaxSize(),
SizeClass::NumMoveSize(size)); // 慢开始算法
void* start = nullptr;
void* end = nullptr;
size_t actual = CentralCache::getinstance()
->FetchRangeObj(start,end,batchNum,size); // 批量拿
if (actual > 1)
_freeLists[index].PushRange(NextObj(start),end,actual-1); // 剩的留本地
return start; // 返回一个给用户
}
三、CentralCache 层(桶级自旋锁):
size_t CentralCache::FetchRangeObj(void*& start,void*& end,size_t n,size_t size){
size_t index = SizeClass::Index(size);
SpanList& list = _spanLists[index];
list._mtx.lock(); // 桶锁:一条链一把
Span* span = GetOneSpan(list,size); // 确保有非空 Span
start = span->_freelist; // 从 Span 切 batch
...
list._mtx.unlock(); // 放锁
return actual;
}内部如果发现 本桶没 Span,会临时放锁→向 PageCache 要整段内存→重新加锁挂回来(防止死锁)。
四、CentralCache → PageCache 拿整段内存
// CentralCache.cc
Span* CentralCache::GetOneSpan(SpanList& list,size_t byte_size){
list._mtx.unlock(); // 解锁,保持层级单调
PageCache::Instance()->_pagemtx.lock(); // 全局页锁
Span* span = PageCache::Instance()->NewPage(
SizeClass::NumMovePage(byte_size)); // 要几页
PageCache::Instance()->_pagemtx.unlock(); // 放页锁
list._mtx.lock(); // 再拿桶锁
list.PushFront(span); // 把新 Span 挂桶
return span;
}五、PageCache 层(按页合并 / 拆分)
// PageCache.cc
Span* PageCache::NewPage(size_t k){
if (!_spanLists[k].Empty()) // 有现成 k 页 Span
return _spanLists[k].PopFront(); // 直接返回
for (size_t n = k+1; n < MAX_SPANS; ++n) // 往后找更大块
if (!_spanLists[n].Empty()){
Span* big = _spanLists[n].PopFront();
Span* spl = new Span; // 切出 k 页
spl->_pageID = big->_pageID;
spl->_n = k;
big->_pageID += k;
big->_n -= k;
_spanLists[big->_n].PushFront(big); // 剩余挂回去
return spl; // 返回给 CentralCache
}
// 仍没有 → 向 OS 拿 128 页再递归切
void* ptr = SystemAlloc(MAX_SPANS-1); // 最后才 mmap / VirtualAlloc
...
}
真正走到系统调用时,一次性拿 1 MB(128×8 KB),后面慢慢切。
性能对比:
#include "CentralCache.h"
#include "PageCache.h"
CentralCache CentralCache::_sInst;
// 获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{
// 查看当前的spanlist中是否有还有未分配对象的span
Span* it = list.Begin();
while (it != list.End())
{
if (it->_freeList != nullptr)
{
return it;
}
else
{
it = it->_next;
}
}
// 先把central cache的桶锁解掉,这样如果其他线程释放内存对象回来,不会阻塞
list._mtx.unlock();
// 走到这里说没有空闲span了,只能找page cache要
PageCache::GetInstance()->_pageMtx.lock();
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
span->_isUse = true;
span->_objSize = size;
PageCache::GetInstance()->_pageMtx.unlock();
// 对获取span进行切分,不需要加锁,因为这会其他线程访问不到这个span
// 计算span的大块内存的起始地址和大块内存的大小(字节数)
char* start = (char*)(span->_pageId << PAGE_SHIFT);
size_t bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
// 把大块内存切成自由链表链接起来
// 1、先切一块下来去做头,方便尾插
span->_freeList = start;
start += size;
void* tail = span->_freeList;
int i = 1;
while (start < end)
{
++i;
NextObj(tail) = start;
tail = NextObj(tail); // tail = start;
start += size;
}
NextObj(tail) = nullptr;
// 1、条件断点
// 2、疑似死循环,可以中断程序,程序会在正在运行的地方停下来
//int j = 0;
//void* cur = span->_freeList;
//while (cur)
//{
// cur = NextObj(cur);
// ++j;
//}
//if (j != (bytes / size))
//{
// int x = 0;
//}
// 切好span以后,需要把span挂到桶里面去的时候,再加锁
list._mtx.lock();
list.PushFront(span);
return span;
}
// 从中心缓存获取一定数量的对象给thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
Span* span = GetOneSpan(_spanLists[index], size);
assert(span);
assert(span->_freeList);
// 从span中获取batchNum个对象
// 如果不够batchNum个,有多少拿多少
start = span->_freeList;
end = start;
size_t i = 0;
size_t actualNum = 1;
while ( i < batchNum - 1 && NextObj(end) != nullptr)
{
end = NextObj(end);
++i;
++actualNum;
}
span->_freeList = NextObj(end);
NextObj(end) = nullptr;
span->_useCount += actualNum;
//// 条件断点
int j = 0;
void* cur = start;
while (cur)
{
cur = NextObj(cur);
++j;
}
if (j != actualNum)
{
int x = 0;
}
_spanLists[index]._mtx.unlock();
return actualNum;
}
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
while (start)
{
void* next = NextObj(start);
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
NextObj(start) = span->_freeList;
span->_freeList = start;
span->_useCount--;
// 说明span的切分出去的所有小块内存都回来了
// 这个span就可以再回收给page cache,pagecache可以再尝试去做前后页的合并
if (span->_useCount == 0)
{
_spanLists[index].Erase(span);
span->_freeList = nullptr;
span->_next = nullptr;
span->_prev = nullptr;
// 释放span给page cache时,使用page cache的锁就可以了
// 这时把桶锁解掉
_spanLists[index]._mtx.unlock();
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
_spanLists[index]._mtx.lock();
}
start = next;
}
_spanLists[index]._mtx.unlock();
}测试结果

可以看到我们的内存池是有明显优势的!!!
今天的更新就到这里,如有错误欢迎指出
评论
精彩的 旅游网站, 保持 保持热情。深表谢意.
素材精彩极了。由衷感谢 独创性。 國家儀典 令人惊叹的 旅行项目, 请继续 继续下去。多谢!