TCP协议
Tcp协议全称为”传输控制协议⼈如其名,要对数据的传输进⾏⼀个详细的控制。
TCP协议段格式

| 字段名称 | 长度(位) | 说明与作用 |
|---|---|---|
| 源端口(Source Port) | 16 位 | 标识发送方应用程序的端口号,用于区分主机上不同的应用程序。 |
| 目的端口(Destination Port) | 16 位 | 标识接收方应用程序的端口号,用于区分主机上不同的应用程序。 |
| 序号(Sequence Number) | 32 位 | 标识本报文段发送的数据的第一个字节的序号,用于实现可靠传输和数据顺序重组。 |
| 确认号(Acknowledgment Number) | 32 位 | 仅当 ACK 标志位为 1 时有效,表示期望收到对方下一个报文段的第一个字节序号,用于确认已正确接收的数据。 |
| 数据偏移(Header Length) | 4 位 | 表示 TCP 报文段首部的长度,以 4 字节为单位,用于确定数据区的起始位置。 |
| 保留(Reserved) | 6 位 | 保留字段,目前必须为 0,供将来使用。 |
| 标志位(Flags) | 6 位 | 每个标志位占 1 位,用于控制 TCP 的连接状态和数据传输: URG:紧急指针有效标志 ACK:确认号有效标志 PSH:推送标志,提示接收方立即将数据交给应用层 RST:复位连接标志 SYN:同步序号标志,用于建立连接 FIN:结束连接标志 |
| 窗口(Window Size) | 16 位 | 表示接收方当前可接收的数据量(以字节为单位),用于流量控制。 |
| 校验和(Checksum) | 16 位 | 用于检验 TCP 报文段在传输过程中是否出现差错,包括首部和数据部分。 |
| 紧急指针(Urgent Pointer) | 16 位 | 仅当 URG 标志位为 1 时有效,表示紧急数据的末尾在报文段数据中的位置。 |
| 任选项(Options) | 可变长度 | 用于提供额外的功能,例如最大报文段长度(MSS)、窗口扩大因子、时间戳等。 |
| 填充(Padding) | 可变长度 | 用于确保 TCP 首部长度为 4 字节的整数倍,以便数据偏移字段正确指示数据区的位置。 |
| 数据区(Data) | 可变长度 | 存放应用层传递给 TCP 的数据,例如 HTTP、FTP 等协议的数据。 |
确认应答(ACK)机制
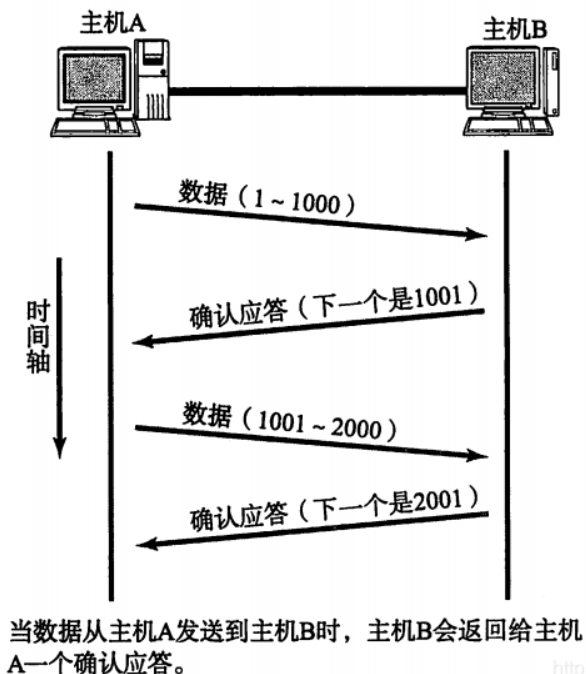
TCP将每个字节的数据都进⾏了编号.即为序列号.
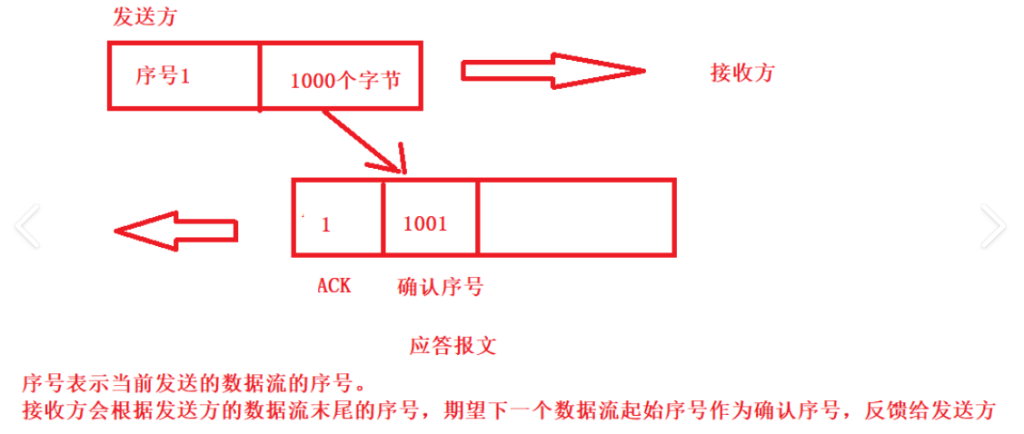
每⼀个ACK都带有对应的确认序列号,意思是告诉发送者,我已经收到了哪些数据;下⼀次你从哪⾥开始
发
超时重传机制
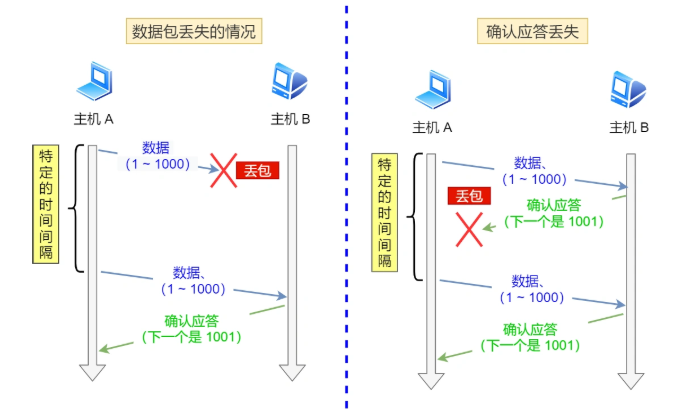
主机A发送数据给B之后,可能因为⽹络拥堵等原因,数据⽆法到达主机B;
如果主机A在⼀个特定时间间隔内没有收到B发来的确认应答,就会进⾏重发
但是,主机A未收到B发来的确认应答,也可能是因为ACK丢失了;
因此主机B会收到很多重复数据.那么TCP协议需要能够识别出那些包是重复的包,并且把重复的丢弃掉.
这时候我们可以利⽤前⾯提到的序列号,就可以很容易做到去重的效果
那么,如果超时的时间如何确定?
•最理想的情况下,找到⼀个最⼩的时间,保证”确认应答⼀定能在这个时间内返回”.
•但是这个时间的⻓短,随着⽹络环境的不同,是有差异的.
•如果超时时间设的太⻓,会影响整体的重传效率;
•如果超时时间设的太短,有可能会频繁发送重复的包;
TCP为了保证⽆论在任何环境下都能⽐较⾼性能的通信,因此会动态计算这个最⼤超时时间.
•Linux中(BSDUnix和Windows也是如此),超时以500ms为⼀个单位进⾏控制,每次判定超时重发
的超时时间都是500ms的整数倍.
•如果重发⼀次之后,仍然得不到应答,等待2500ms后再进⾏重传. • 如果仍然得不到应答,等待4500ms进⾏传.依次类推,以指数形式递增.
•累计到⼀定的重传次数,TCP认为⽹络或者对端主机出现异常,强制关闭连接
连接管理机制
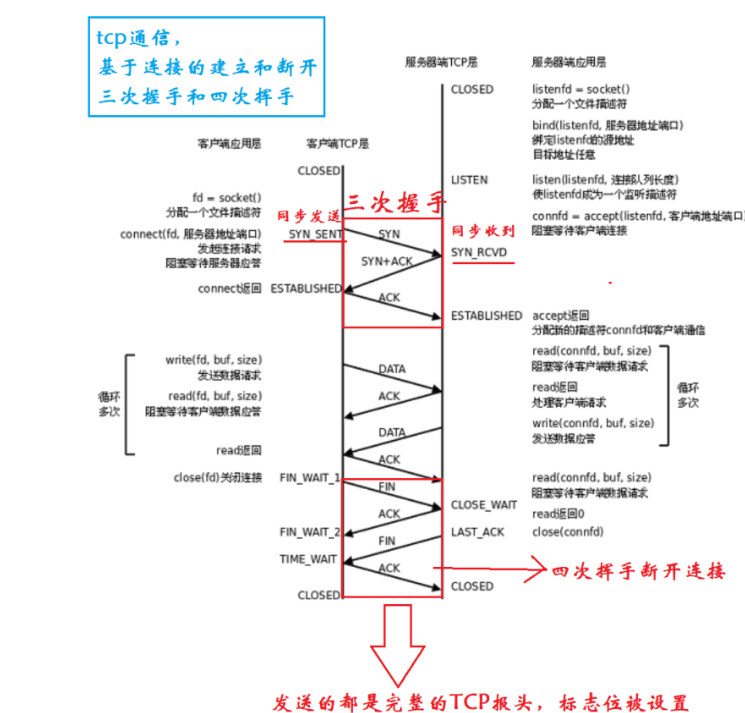
一、TCP 通信的核心特点
面向连接:通信前必须建立连接(三次握手)
可靠传输:通过确认应答、序号、重传机制保证数据可靠
双向通信:全双工通信,双方可同时收发数据
连接终止需四次挥手
在三次握手中和四次挥手中客户端和服务端状态变化
| 步骤 | 方向 | 动作 | 状态变化 |
|---|---|---|---|
| 1 | 客户端 → 服务器 | 发送 SYN(同步序列号) | 客户端:SYN_SENT |
| 2 | 服务器 → 客户端 | 回复 SYN + ACK(确认) | 服务器:SYN_RCVD |
| 3 | 客户端 → 服务器 | 发送 ACK(确认) | 双方:ESTABLISHED |
| 步骤 | 方向 | 动作 | 状态变化 |
|---|---|---|---|
| 1 | 客户端 → 服务器 | 发送 FIN(结束标志) | 客户端:FIN_WAIT_1 |
| 2 | 服务器 → 客户端 | 回复 ACK(确认) | 服务器:CLOSE_WAIT,客户端:FIN_WAIT_2 |
| 3 | 服务器 → 客户端 | 发送 FIN(我也要关闭) | 服务器:LAST_ACK |
| 4 | 客户端 → 服务器 | 回复 ACK(确认) | 客户端:TIME_WAIT(等待2MSL),服务器:CLOSED |
下面是总的tcp转换图:
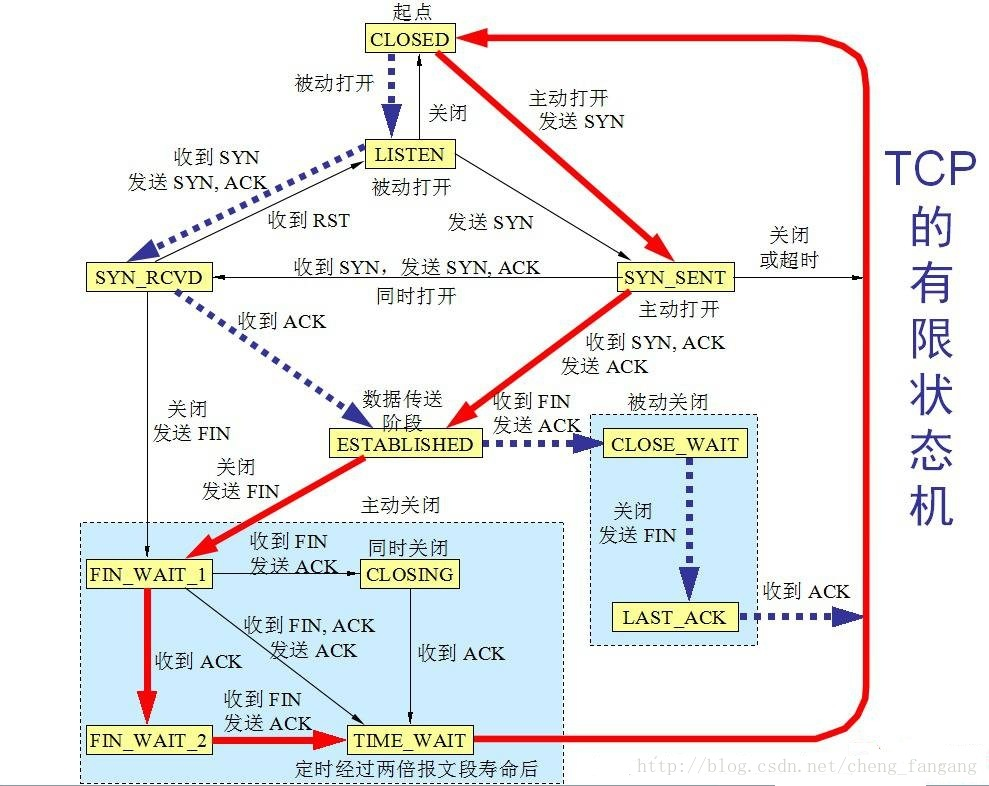
较粗的虚线表⽰服务端的状态变化情况;
较粗的实线表⽰客⼾端的状态变化情况;
CLOSED是⼀个假想的起始点,不是真实状态;
理解TIME_WAIT状态
TCP协议规定,主动关闭连接的⼀⽅要处于TIME_WAIT状态,等待两个MSL(maximumsegment
lifetime)的时间后才能回到CLOSED状态
故我们当时使用tcp绑定端口时需要过一会才能使用就是这个原因
但是值得我们注意的是服务器主动关闭连接会导致 TIME_WAIT 堆积,占用五元组,最终耗尽端口或拒绝新连接,尤其在高并发短连接场景下非常危险。
滑动窗⼝
刚才我们讨论了确认应答策略,对每⼀个发送的数据段,都要给⼀个ACK确认应答.收到ACK后再发送下
⼀个数据段.这样做有⼀个⽐较⼤的缺点,就是性能较差.尤其是数据往返的时间较⻓的时候
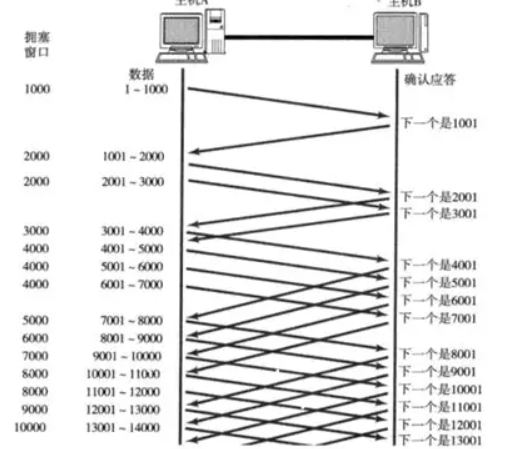
既然这样⼀发⼀收的⽅式性能较低,那么我们⼀次发送多条数据,就可以⼤⼤的提⾼性能(其实是将多个
段的等待时间重叠在⼀起了)
1.窗⼝⼤⼩指的是⽆需等待确认应答⽽可以继续发送数据的最⼤值.上图的窗⼝⼤⼩就是4000个字
节(四个段).
2.发送前四个段的时候,不需要等待任何ACK,直接发送;
3.收到第⼀个ACK后,滑动窗⼝向后移动,继续发送第五个段的数据;依次类推;
4.操作系统内核为了维护这个滑动窗⼝,需要开辟发送缓冲区来记录当前还有哪些数据没有应答;只有确认应答过的数据,才能从缓冲区删掉;
5.窗⼝越⼤,则⽹络的吞吐率就越⾼
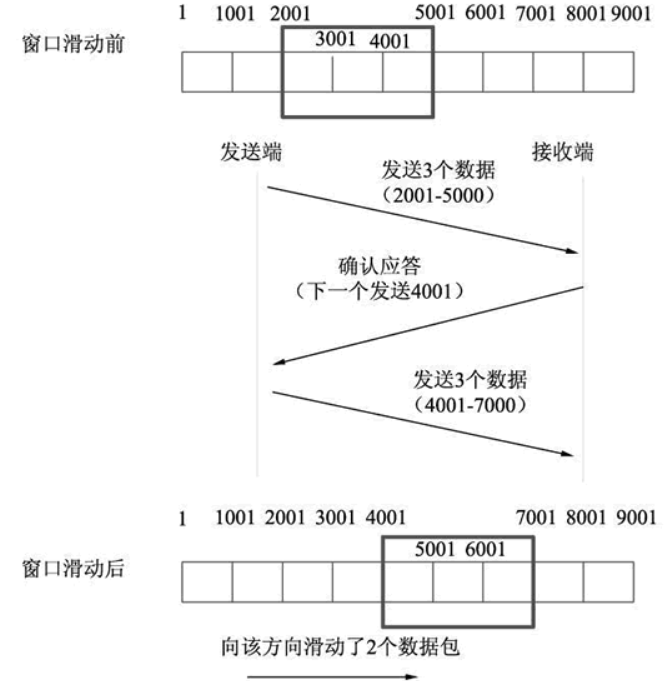
那么如果出现了丢包,如何进⾏重传?这⾥分两种情况讨论.
情况⼀:数据包已经抵达,ACK被丢了
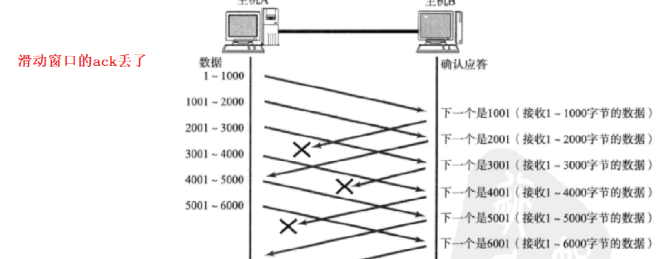
这种情况下,部分ACK丢了并不要紧,因为可以通过后续的ACK进⾏确认
情况⼆:数据包就直接丢了
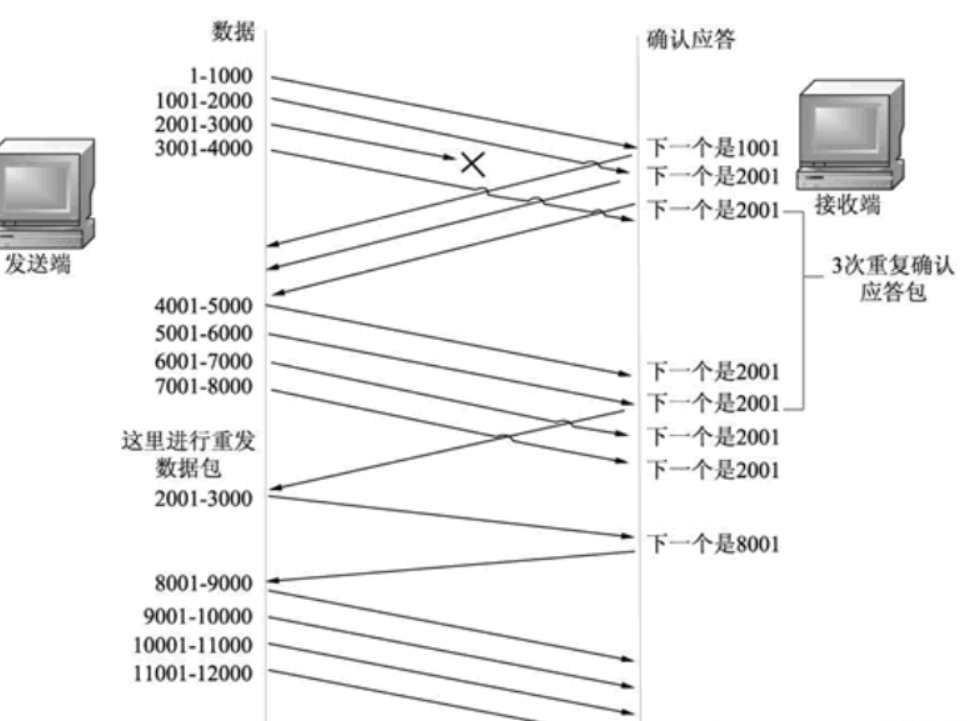
1、当某⼀段报⽂段丢失之后,发送端会⼀直收到2001这样的ACK,就像是在提醒发送端”我想要的是
2001″ ⼀样;
2、如果发送端主机连续三次收到了同样⼀个”2001″这样的应答,就会将对应的数据0001-3000重
新发送;
3、这个时候接收端收到了2001之后,再次返回的ACK就是7001了(因为2001-7000)接收端其实之前
就已经收到了,被放到了接收端操作系统内核的接收缓冲区中;
这种机制被称为”⾼速重发控制”(也叫”快重传”)
流量控制
接收端处理数据的速度是有限的.如果发送端发的太快,导致接收端的缓冲区被打满,这个时候如果发送
端继续发送,就会造成丢包,继⽽引起丢包重传等等⼀系列连锁反应.
因此TCP⽀持根据接收端的处理能⼒,来决定发送端的发送速度.这个机制就叫做流量控制(Flow
Control)
1.接收端将⾃⼰可以接收的缓冲区剩余空间⼤⼩放⼊TCP⾸部中的”窗⼝⼤⼩”字段,通过ACK端通
知发送端;
2.窗⼝⼤⼩字段越⼤,说明⽹络的吞吐量越⾼;
3.接收端⼀旦发现⾃⼰的缓冲区快满了,就会将窗⼝⼤⼩设置成⼀个更⼩的值通知给发送端;
4.发送端接受到这个窗⼝之后,就会减慢⾃⼰的发送速度;
5.如果接收端缓冲区满了,就会将窗⼝置为0;这时发送⽅不再发送数据,但是需要定期发送⼀个窗⼝
探测数据段,使接收端把窗⼝⼤⼩告诉发送端
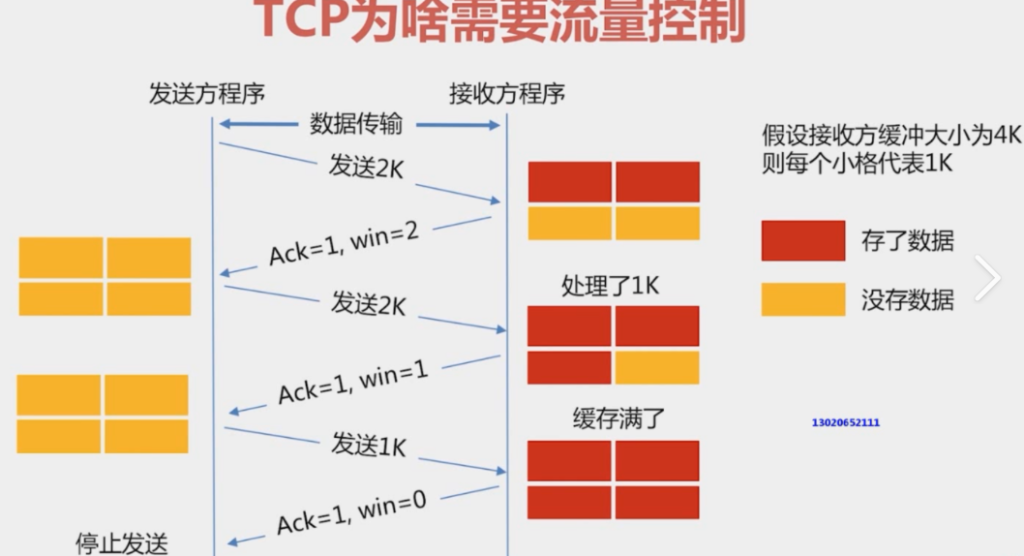
接收端如何把窗⼝⼤⼩告诉发送端呢?回忆我们的TCP⾸部中,有⼀个16位窗⼝字段,就是存放了窗⼝⼤⼩;
那么问题来了,16位数字最⼤表⽰65535,那么TCP窗⼝最⼤就是65535字节么?
实际上,TCP⾸部40字节选项中还包含了⼀个窗⼝扩⼤因⼦M,实际窗⼝⼤⼩是窗⼝字段的值左移M位
拥塞控制
虽然TCP有了滑动窗⼝这个⼤杀器,能够⾼效可靠的发送⼤量的数据.但是如果在刚开始阶段就发送⼤量
的数据,仍然可能引发问题.
因为⽹络上有很多的计算机,可能当前的⽹络状态就已经⽐较拥堵.在不清楚当前⽹络状态下,贸然发送
⼤量的数据,是很有可能引起雪上加霜的.
TCP引⼊慢启动机制,先发少量的数据,探探路,摸清当前的⽹络拥堵状态,再决定按照多⼤的速度传输
数据;
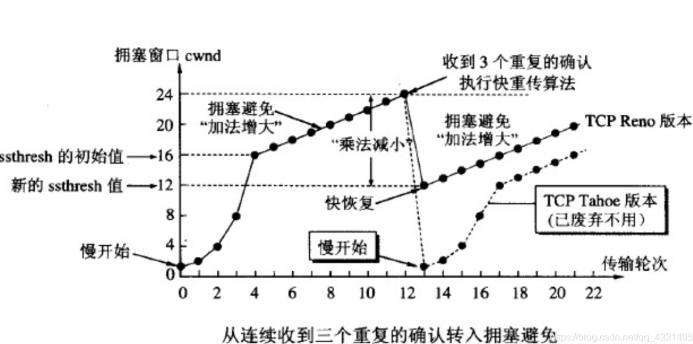
此处引⼊⼀个概念称为拥塞窗⼝
发送开始的时候,定义拥塞窗⼝⼤⼩为1;
每次收到⼀个ACK应答,拥塞窗⼝加1;
每次发送数据包的时候,将拥塞窗⼝和接收端主机反馈的窗⼝⼤⼩做⽐较,取较⼩的值作为实际发送的窗⼝;
像上⾯这样的拥塞窗⼝增⻓速度,是指数级别的.”慢启动”只是指初使时慢,但是增⻓速度⾮常快.
为了不增⻓的那么快,因此不能使拥塞窗⼝单纯的加倍.
此处引⼊⼀个叫做慢启动的阈值
当拥塞窗⼝超过这个阈值的时候,不再按照指数⽅式增⻓,⽽是按照线性⽅式增⻓
延迟应答
如果接收数据的主机⽴刻返回ACK应答,这时候返回的窗⼝可能⽐较⼩.
假设接收端缓冲区为1M.⼀次收到了500K的数据;如果⽴刻应答,返回的窗⼝就是500K;
但实际上可能处理端处理的速度很快,10ms之内就把500K数据从缓冲区消费掉了;
在这种情况下,接收端处理还远没有达到⾃⼰的极限,即使窗⼝再放⼤⼀些,也能处理过来;
如果接收端稍微等⼀会再应答,⽐如等待200ms再应答,那么这个时候返回的窗⼝⼤⼩就是1M;
数量限制:每隔N个包就应答⼀次;
时间限制:超过最⼤延迟时间就应答⼀次;
⼀定要记得,窗⼝越⼤,⽹络吞吐量就越⼤,传输效率就越⾼.我们的⽬标是在保证⽹络不拥塞的情况下
尽量提⾼传输效率;
那么所有的包都可以延迟应答么?肯定也不是;
具体的数量和超时时间,依操作系统不同也有差异;⼀般N取2,超时时间取200ms
⾯向字节流
创建⼀个TCP的socket,同时在内核中创建⼀个发送缓冲区和⼀个接收缓冲区;
调⽤write时,数据会先写⼊发送缓冲区中;
1.如果发送的字节数太⻓,会被拆分成多个TCP的数据包发出;
2.如果发送的字节数太短,就会先在缓冲区⾥等待,等到缓冲区⻓度差不多了,或者其他合适的时机发送出去;
3.接收数据的时候,数据也是从⽹卡驱动程序到达内核的接收缓冲区;然后应⽤程序可以调⽤read从接收缓冲区拿数据;
另⼀⽅⾯,TCP的⼀个连接,既有发送缓冲区,也有接收缓冲区,那么对于这⼀个连接,既可以读数据,也可以写数据.这个概念叫做全双⼯
由于缓冲区的存在,TCP程序的读和写不需要⼀⼀匹配,例如:
写100个字节数据时,可以调⽤⼀次write写100个字节,也可以调⽤100次write,每次写⼀个字节;
读100个字节数据时,也完全不需要考虑写的时候是怎么写的,既可以⼀次read100个字节,也可以
⼀次read⼀个字节,重复100次
TCP/UDP对⽐
我们说了TCP是可靠连接,那么是不是TCP⼀定就优于UDP呢?TCP和UDP之间的优点和缺点,不能简单,
绝对的进⾏⽐较
1.TCP⽤于可靠传输的情况,应⽤于⽂件传输,重要状态更新等场景;
2.UDP⽤于对⾼速传输和实时性要求较⾼的通信领域,例如,早期的QQ,视频传输等.另外UDP可以
⽤于⼴播;
归根结底,TCP和UDP都是程序员的⼯具,什么时机⽤,具体怎么⽤,还是要根据具体的需求场景去判定
今天的更新就到这里,如有错误欢饮评论区指出
评论
还没有任何评论,你来说两句吧!